Designing A Recommendation System For Search In Ecommerce
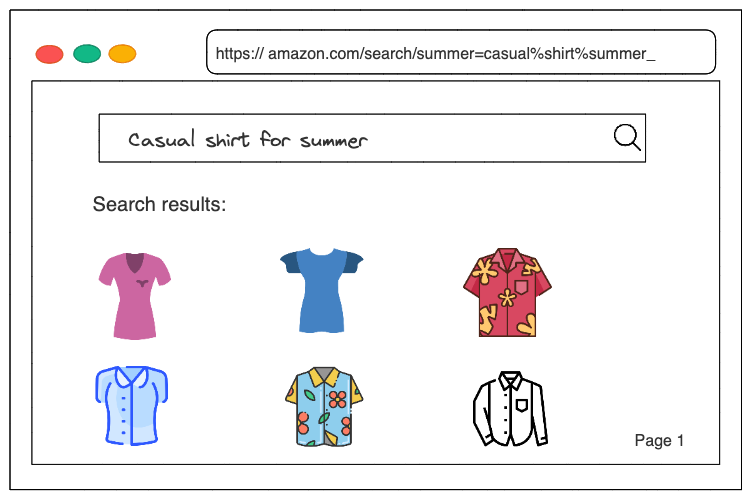
data-science system-design search On e-commerce sites like Amazon, there may be millions of different products to choose from. For instance, a customer on Amazon could type in "casual shirt for summer" and receive a list of available shirts. A system has been set up in the background that retrieves images related to the user’s query, ranks them according to their similarity to the query, and then shows them to the user.
In this post, I describe how to create a search system that works in a manner similar to that of e-commerce platforms by taking a user’s text query and returning a list of relevant product images.
Basic requirements
To summarize the problem statement, we are designing an image search system that retrieves images similar to the user query, ranks them based on their similarities to the text query, and then displays them to the user. For simplicity, we make some basic assumptions which includes:
- A user can only input text queries (images or videos queries are not allowed).
- We do not need to personalize the result of the search system.
- We have a dataset of say one million
<text query, image>pairs for model training. - The model uses image metadata and pixels. Also, users can only click on an image and we can construct training data online and label them based on user interactions.
1. Overview of the search system
As shown in Figure 1.2, the search system takes a text query as input and outputs a ranked list of images sorted by their relevance to the text query.
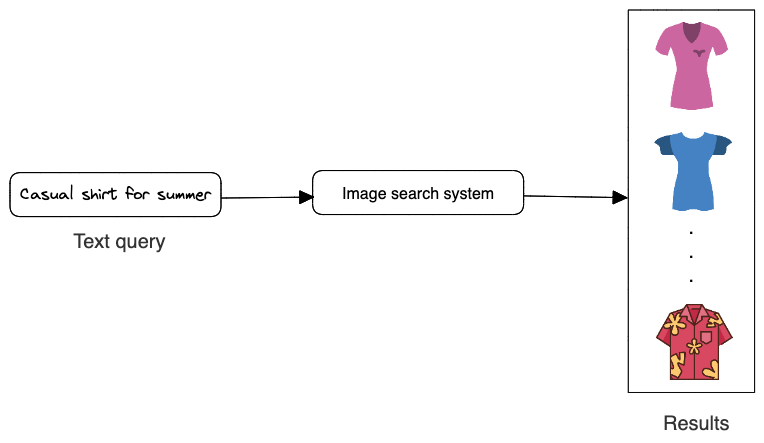
This kind of problem is known as a ranking problem. In general, the goal of ranking problems is to rank a collection of items such as images, websites, products, etc., based on their relevance to a query, so that more relevant items appear higher in the search results. Many ML applications, such as recommendation systems, search engines, document retrieval, and online advertising, can be framed as ranking problems.
In order to determine the relevance between an image and a text query, we utilize both image visual content and the image’s textual data. An overview of the design can be seen in Figure 1.3.

1.1 Text search
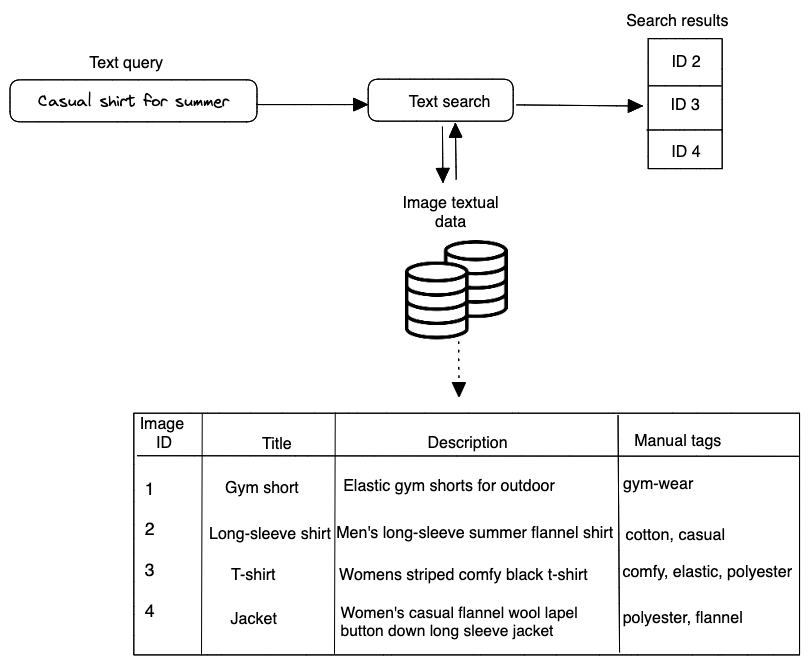
Images that have titles, descriptions, or tags that are the most comparable to the text query are displayed as the results of the \(\textbf{text search}\). When a user enters in a text query like \(\textit{casual shirts for summer}\), Figure 1.4 demonstrates how text search functions. Using full-text search in a database is one method to find the image description that matches the text query the most.
Full-text search (FTS) is the process of searching a portion of text within a large collection of electronically recorded text data and providing results that include part or all of the terms in the search [2]. It retrieves documents that don’t perfectly match the search criteria. Documents here refers to database entities containing textual data.
You may enhance a FTS with search tools like fuzzy-text and synonyms in addition to looking for specific keywords. This implies that, for example, if a user searches for “cats and dogs,” an application supported by FTS may be able to return results that include simply “cats” or “dogs,” the words in a different order (“dogs and cats,” or “cat”), or alternative spellings of the terms (“dog,” or “cat”) [3]. Applications can better infer the user’s intent thanks to this, which speeds up the return of relevant results. This technique is not based on machine-learning hence it is fast as there’s no training cost involved. Many search engine companies use search engines such as Elasticsearch [4], MongoDB Atlas Search [2] to return the results of text queries similar to the catalog queries as seen in Figure 1.4.
1.2. Image visual search
This component outputs a list of images after receiving a text query as input. Based on how closely the text query and the image resemble each other, the images are ranked. \(\textbf{Representation learning}\) is a method that is frequently used to do this.
In representation learning, a model is trained to turn data like images and texts into representations referred to as embeddings. Another way to describe it is that the model converts the images and text queries into points in the embedding space, an N-dimensional space. These embeddings are trained so that nearby embeddings in the embedding space exist for similar images [1].
The text query and image are encoded individually using two encoders in this method. This is significant because words and images must be translated into numerical representations that computers can understand, known as “embeddings,” since computers only comprehend numerical data. In order to create an embedding vector for all of the images of the products that are currently accessible, we first apply a machine learning model to encode the images. Figure 1.5 illustrates how similar images are mapped onto two points in close proximity within the embedding space. The text encoder we employ creates an embedding vector from the text after that. Lastly, we use a dot product of their representation to determine the similarity score between the image and text embedding.

We compute the dot product between the text and each image in the embedding space, then rank the images according to their similarity scores in order to determine which images are most visually and semantically comparable to the text query.

2. Data Preparation for Training
2.1. Data engineering
We assume we are given an annotated dataset to train and evaluate the model. We could have users, image and user-image interactions data.
2.1.1. Images
The system stores catalog items and their metadata. Table 1.1 shows a simplified example of image metadata
| Image ID | Upload time | Manual tags |
|---|---|---|
| 10 | 105743135 | cotton, polo |
| 193 | 1958351341 | long-sleeve, flannel, polyester |
Table 1.1: Image metadata
2.1.2. User-image interactions data
Many kinds of user interactions are contained in interaction data. The type of queries users enter and their interactions with it may be revealed by this kind of data. Clicks, impressions, and purchases (conversion, add-to-cart, etc.) are the three main sorts of interactions, albeit they could be noisy. Table 1.2 displays a condensed example of user-image interaction metadata; we shall discuss this further.
| User ID | Text query | Displayed image ID | Interaction type | Timestamp |
|---|---|---|---|---|
| 10 | White cotton polo | 9 | Click | 1658451365 |
| 193 | Men's long sleeve summer flannel shirt | 15 | Click | 1648452360 |
| 104 | Women blouse perfect for winter | 7543 | Purchase | 1748452261 |
| 1345 | Children christmas wear for winter with red cap | 15 | Click | 1848451367 |
2.2 Feature engineering
Nearly all algorithms for machine learning only accept numeric input values. During this step, unstructured data like texts and images must be transformed into a numerical representation. We outline the process for getting the text and image data ready for the model.
2.1. Preparing the text data
As shown in Figure 1.7, text is typically represented asa numerical vector using three steps: text tokenization, text normalisation and token to IDs [5]
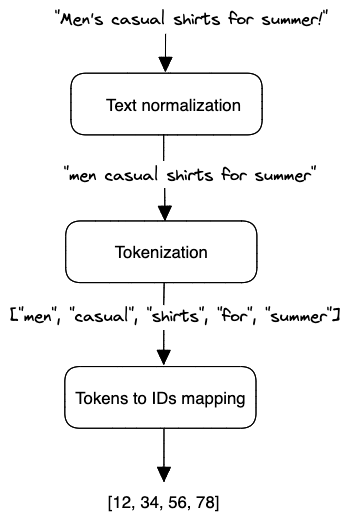
Text normalisation
Tokens are a basic meaningful unit of a sentence or a document. They can consist of words, phrases, subwords, or characters. Normalization is the process of converting a token into its base form. It is helpful in reducing the number of unique tokens present in the text, removing the variations in a text and cleaning it by removing redundant information. Basic methods for text normalization includes: converting all letters to lowercase to retain the meanings of words, trimming whitespaces, remove accent marks, lemmatization and stemming, removing punction marks, etc.
Tokenization
Tokenization is breaking the raw text into small chunks. Tokenization breaks the raw text into words, sentences called tokens. Tokenization helps in interpreting the meaning of the text by analyzing the sequence of the words. For example, the text \(\textit{“Brown chelsea leather boots perfect for winter”}\) can be tokenized to ["Brown", "chelsea", "leather", "boots", "perfect", "for", "winter"]. If the text is split into words using some separation technique it is called word tokenization and same separation done for sentences is called \(\textit{sentence tokenization}\). There are various tokenization techniques available which can be applicable based on the language and purpose of modeling, they include:
-
\(\textbf{Subword tokenization:}\) This process split text into subwords (n-gram characters). In this method, the most often used words are assigned distinctive identifiers, and the less frequently used terms are divided into smaller words that best express the meaning on their own. As an illustration, if the word “dark” occurs frequently in a text, it will be given a unique ID, but the terms “darker” and “darkest”, which are uncommon and appear less frequently in a text, will be divided into subwords such as “dark”, “er”, and “est”. This aids in preventing the language model from learning “darker” and “darkest” as two distinct terms and enables the training process to detect the unknown words in the data set. There are various kinds of subword tokenization, including Byte-Pair Encoding (BPE), WordPiece, Unigram Language Model, SentencePiece.
-
\(\textbf{White Space Tokenization:}\) In this process entire text is split into words by splitting them from whitespaces. This is the fastest tokenization technique but works only for languages like English in which the white space breaks apart the sentence into meaningful words.
-
\(\textbf{Dictionary Based Tokenization:}\) In this method the tokens are found based on the tokens already existing in the dictionary. If the token is not found, then special rules are used to tokenize it. It is an advanced technique compared to whitespace tokenizer.
-
\(\textbf{Rule Based Tokenization:}\) In this technique, a set of rules are created for the specific problem. The tokenization is done based on the rules. For example creating rules bases on grammar for particular language.
Tokens to IDs mapping
Once we have tokens, we need to convert them to numerical values. This can done using Lookup table or hashing.
-
\(\textbf{Lookup table:}\) In this method, each unique token is mapped to an ID. Next, a lookup table is created to store these 1:1 mappings. Lookup tables has its strengths which includes speed as it is easy to convert tokens to IDs and also convert the IDs back to tokens using a reverse index table. However, downside is that it stores the table in a memory hence having a large number of tokens requires huge memory space. Also, it cannot handle new or unseen words properly.
-
\(\textbf{Hashing:}\) Compared to lookup tables, hashing also known as “feature hashing”, or “hashing trick” is a memory efficient method that uses hash function to obtain IDs, without keeping a lookup table. We know that as models are trained with corpus with larger sizes, it produces vocabularies that take more and more memory space to store [6]. For efficiency purposes, these lookup tables are stored in RAM for quick token-id mapping and can slow down the operations once their size gets too big. By using a hashing, we can get rid of such memory-consuming vocabularies entirely and a hash function is used for token-id mapping instead. With a given string, a hash function is capable of returning a numerical value, a hash value, that’s unique to that string and use it as token id. Since there’s no fix-sized vocabulary involved, all tokens can now be assigned to a number, no matter the model has seen it before or not [6]. The downside is that after hashing, we cannot convert IDs back to tokens.
2.2 Preparing image data
In the earlier section 1, we explained the goal is to design an image search system that retrieves images similar a user’s text query, rank them based on their similarities to the text query, and then display them to the user. Since the model returns an image as output, we need to preprocess catalog images. The most common image preprocessing operations are [1]:
- \(\textbf{Resizing:}\) Models usally require fixed image sizes (e.g. \(224 * 224\))
- \(\textbf{Scaling:}\) Scale pixel values of each image to be in the range of 0 and 1
- \(\textbf{Z-score standardization:}\) Scale pixel values to have a mean of 0 and variabce of 1
- \(\textbf{Consistent color mode:}\) Ensure images have a consistent color mode (e.g. RGB or CMYK)
3. Model Development
3.1. Embedding Model Selection
As discussed in the Overview of the search system and visualised in Figure 1.6, text queries are converted into embeddings by a text encoder, and images are converted into embeddings by an image encoder. In this section, we examine possible model architectures for each encoder.
3.1.1 Text encoder
A typical text encoder’s input and output are shown in Figure 1.8.
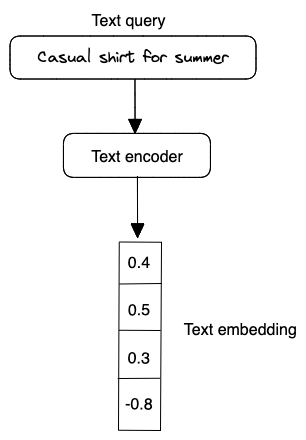
The text encoder converts texts into a vector representation. For example, if two separate sentencs have similar meanings, their embeddings are more similar. To build the text encoder, two broad categories are widely available: statistical methods and machine learning based methods.
Statistical methods
These methods rely on statistics to convert meaningful text into number (vector) representation. Three popular methods are:
- Index-Based Encoding
- Bag of Words (BoW)
- Term Frequency Inverse Document Frequency (TF-IDF)
\(\textbf{Index-Based Encoding}\).
As the name implies requires all the unique words in a document, then it assigns an index. For instance, suppose we have the following 3 sentences namely ["Men's long-sleeve summer flannel shirt", "White cotton polo", "Women blouse perfect for winter"]. Then our corpus (collection of unique words in a document) would look like this ["men", "long-sleeve", "summer", "flannel", "shirt", "white", "cotton", "polo", "women", "blouse", "perfect", "for", "winter"].
We assign an index to each word like: “men”: 1, “cotton”: 2, “summer”:3, “white”: 4, “polo”: 5 and so on. Now that we have assigned a unique index to all the words so that based on the index we can uniquely identify them and replace the words in each sentence with their respective indexes. The text query “White cotton polo” becomes [4, 2, 5] which is understandable to any machine.
But there is an issue which needs to be addressed first and that is the consistency of the input. Our input needs to be of the same length as our model, it cannot vary. It might vary in the real world but needs to be taken care of when we are using it as input to our model.
Now as we can see the first sentence (“Men’s long-sleeve summer flannel shirt”) has (5) words, but the next sentence (“White cotton polo”) has (3) words, this will cause an imbalance in our model. To overcome this, we use max padding, which means we take the longest sentence from our document corpus and we pad the other sentence to be as long. This means if all of my sentences are of (5) words and one sentence is of (3) words, we will make all the sentences of (5)words.
To add the extra word, recall while assigning indexes we started from (1) not (0). We use (0) as our padding index. This also means that we are appending nothing to our actual sentence as 0 doesn’t represent any specific word, hence the integrity of our sentences are intact
\(\textbf{Bag of Words (BoW)}\). BoW is another form of encoding where we use the whole data corpus to encode our sentences. BoW models sentence-word occurreences by creating a matrix with rows representing senetences and columns representing word appearance or frequencies.
Suppose, our data corpus consist of the following:
There are 2 kinds of BoW:
- \(\textbf{Binary BoW:}\) We encode 1 or 0 for each word appearing or non-appearing in the sentence. We do consider the frequency of the word appearing in that sentence.
- \(\textbf{BoW:}\) We consider the frequency of each word occurring in that sentence.
An example of BoW is shown in Table 1.3
| men | long-sleeve | summer | flannel | shirt | white | cotton | polo | women | blouse | perfect | for | winter | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| men's long-sleeve summer flannel shirt | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| women white cotton polo shirt | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | |
| for women cotton blouse perfect for winter | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 2 | 1 |
BoW is a simple method that computes sentence representations fast, but has the following limitations [1]:
- It does not consider the order of words in a sentence. For example, “fitted shirts for tall men” and “tall men for fitted shirts” would have the same BoW representation
- The obtained representation does not capture the semantic and contextual meaning of the sentence. For exampole, two sentences with the same meaning but different words have a totally different represntation.
- The representation vector is sparse. The size of the representation vector is equal to the total number of unique tokens we have. This number is usually large, so each sentem¡nce is mostly filled with zeroes.
\(\textbf{Term Frequency Inverse Document Frequency (TF-IDF)}\). In this method, we give every word a relative frequency coding with respect to the current sentence and the whole document [7]
Term Frequency: Is the occurrence of the current word in the current sentence with respect to the total number of words in the current sentence.
\[ tf_{ij} = \frac{n_{i,j}}{\sum_{k}n_{i,j}}\]
Inverse Data Frequency: Log of Total number of words in the whole data corpus with respect to the total number of sentences containing the current word.
\[ idf(w) = log \big(\frac{N}{df_{t}}\big)\]
TF-IDF is a numerical statistic intended to reflect how important a word is to a document in a collection or corpus. It creates the same sentence-word matrix like in BoW but it normalizes the matrix based on the frequency of words. Since TF-IDF gives less weight to frequent words, its representations are usually better than BoW. However, it has its drawbacks such as: it does not consider the order of words in a sentence, the obtained representations are sparse and does not even capture the semantic meaning of the sentence.
In summary, statistical methods for text encoding are usually fast however they do not capture the contextual meaning of sentences. ML-based methods which we will discuss next address these issues.
Machine learning-based methods
In these methods, an ML model converts sentences into meaningful word embeddings so that the distance between two embeddings reflects the semantic similarity of the corresponding words. For example, if two words such as “cotton” and “wool”, are semantically similar, their embeddings are close in the embedding space.
There are various ML-based approaches for transforming texts into word embeddings, examples include: Word2Vec, GloVe, Transformer-based architectures.
\(\textbf{Word2Vec:}\) word2vec [8] is not a singular algorithm, rather, it is a family of model architectures and optimizations that can be used to learn word embeddings from large datasets. Word2vec is a shallow, two-layer Artificial Neural Network that processes text by converting them into numeric “vectorized” words. It’s input is a large word corpus and output a vector space, usually hundreds of dimensions, with each unique word in the corpus represented with that vector space generated. It is used to reconstruct linguistic contexts of words into numbers. Word vectors are positioned in the vector space in such a way that the words that share common contexts are located in close proximity to one another in that multidimensional space, in layman terms the words that almost mean the same will be placed together.
There are two methods for learning representations of words in word2vec:
- \(\textbf{Continuous bag-of-words model:}\) predicts the middle word based on surrounding context words. The context consists of a few words before and after the current (middle) word. This architecture is called a bag-of-words model as the order of words in the context is not important.
- \(\textbf{Continuous skip-gram model:}\) predicts words within a certain range before and after the current word in the same sentence.
We will not explain in detail the other ML-based approaches for transforming texts.
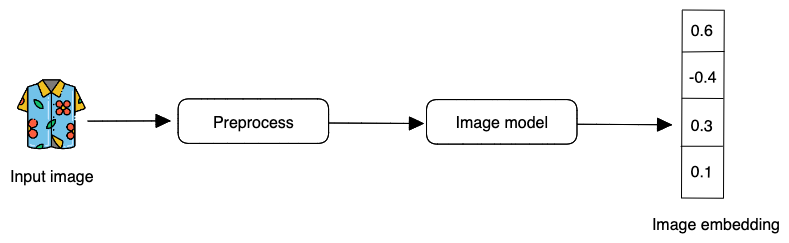
3.1.2 Image encoder
For encoding images, we propose using neural networks because it has proven to be good at handling texts and images and able to produce the embeddings needed for representation learning. CNN-based architectures such as Residual network or ResNet [9] has an impressive \(152\) layers. The key to the model design is the idea of residual blocks that make use of shortcut connections. These are simply connections in the network architecture where the input is kept as-is (not weighted) and passed on to a deeper layer, e.g. skipping the next layer.
3.2. Model Training
In order to retrieve images similar to the text query, a model must learn representations (embedding) during training. In this section, we discuss how to train the text and image encoder using \(\textbf{contrastive learning}\) [10]. In this approach, we train a model to distinguish between similar <text query, image> pair from dissimilar ones. In other words, we provide the model with a <text query, image> pair, one similar pair , and a few disimilar pair. During training, the model learns to produce representations in which similar text query - image pair resemble the pair, than other pairs.
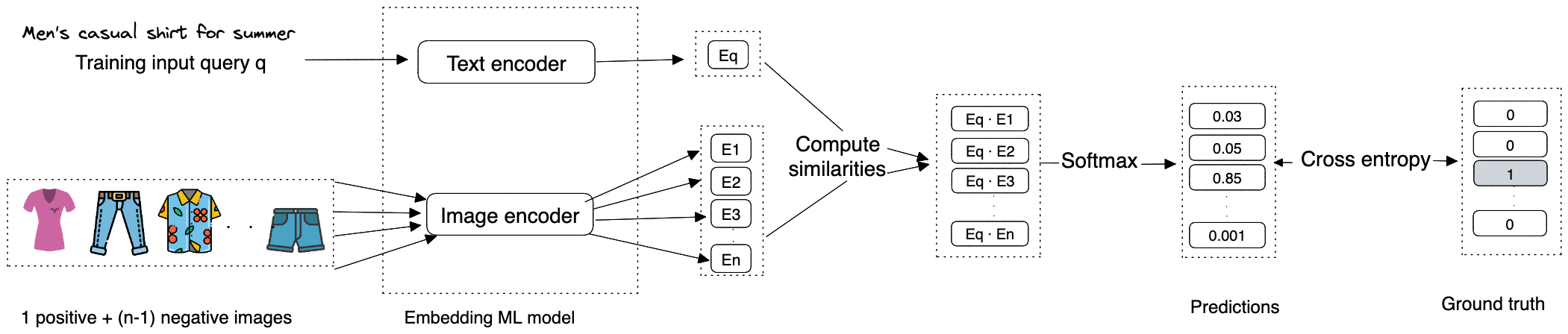
Constructing the dataset
As described earlier, each data point used for training contains a query-image pair, a positive query-image pair that’s similar to the pair, and \(n-1\) negative pairs that are dissimilar to the pair. The ground truth label of the data point is the index of the positive text query-image pair. As Figure 2.0 depicts, along with a query-image pair \(q\), we have \(n\) other images of which one is similar to the \(q\) (casual men’s beach summer shirt) and the other \(n-1\) images are dissimilar. The ground truth label for this data point is the index of the positive image, which is \(3\) (the third image among the \(n\) images in Figure 2.0)

To construct a data point, we randomly choose a text query - image pair and \(n-1\) negative text queries since our input is the text query. To select a positive image, we have the following options:
- \(\textbf{Use human judgement:}\) Here, we rely on humans manually finding similar search query-image pairs. The advantage is that we have accurate correctly labelled data however it is time-consuming and expensive.
- \(\textbf{Use interactions such as user clicks, purchases as proxy for similarity:}\) This approach does not require manual and can generate data automatically when a user interacts (clicks, purchase) an image. We assume similarity is based on interaction dara and the interacted image is similar to the search query. However, interactions data is very noisy as users sometimes click on images even when it is not similar to thee text query. Also, the data is very sparse and these problems in turn leads to poor performance.
3.3 Ranking and loss computation
Ranking is a slower—but more precise—step to score and rank top candidates. As we’re processing fewer items (i.e., hundreds instead of millions), we have room to add features that would have been infeasible in the retrieval step (due to compute and latency constraints). Such features include item and user data, and contextual information. We can also use more sophisticated models with more layers and parameters [11].
Loss function selection
The goal of the training is to optimize the model parameters so that similar text query - image pairs have embeddings close to each other in the embedding space. Ranking can be modeled as a learning-to-rank or classification task, with the latter being more commonly seen. In this article, we are proposing using deep learning deep learning where the final output layer is a softmax over a catalog of images. We could also use a sigmoid predicting the likelihood of user interaction (e.g., click, purchase) for each query-image pair. The loss computation steps can be summarised as follows:
- \(\textbf{Generate embeddings:}\) Use text and image encoders to generate the embeddings for the search query and catalog images.
- \(\textbf{Compute similarities:}\) Compute the similarities beetween the text query’s embedding and the catalog image embeddings. There are different measures of similarites we could use and they have their pros and cons, examples include dot product, cosine similarity, euclidean distance among others.
- \(\textbf{Softmax function:}\) This is applied over the computed distances to ensure the values sum up to one, by so doing we can interpret the similarity values as probabilities.
- \(\textbf{Cross-entropy:}\) Cross-entropy measures how close the predicted probabilities are to the ground trith labels. When the predicted probabilities are close to the ground truthm it shows the embeddings can distinguish the positive query-image pair from the negative ones.
Figure 2.1 visualises the system architecture, we see the model takes text query as input, produces embedding for this query, compute the similarity between this embedding and the embedding of each image in the catalog.
4. Evaluation
Evaluating the performance of the predictions is a critical step and this section focuses on this. The evaluation merics can be classified into offline and online metrics. Aminian & Alex Xu (2023) covered this in-depth which would I summarised in the subsequent subsections.
4.1. Offline metrics
Offline metrics are the metrics that evaluate the performance of the model and they are typically not business related (in the sense that they do not measure KPIs business care about such as click-through rate) but are still useful to evaluate the model’s performance on an evaluation data. Offline metrics suitable for this problem are Precision@k, mAP, Recall@k, Mean reciprocal rank (MRR).
Precision@k
This metric measures the proportion of relevant items among the top \(k\) items in the ranked output list. In the evaluation dataset, a given text query is associated with only one positive image since we are using a contrastive learning approach. That means the numerator of the precision@k formula is at most \(1\) which leads to low precision@k values.
\[ \text{precision@k} = \frac{\text{Number of relevant images among the top \(k\) images in the ranked list}}{k} \]
For instance, for a given text query, even if we rank its associatd images at the top of the list, the precision@5 is only \(\frac{1}{5}= 0.2\). Due to this limitation, precision metrics, such as precision@k and mAP are not suitable.
Recall@k
This metric measures the ratio between the number of relevant images in the search results and the total number of relevant images.
\[ \text{recall@k} = \frac{\text{Number of relevant images among the top \(k\) images}}{\text{Total number of relevant images}} \]
Since we are using contrastive learning (one similar query-image pair and other dissimilar images), the denominator (total number of relevant images) is always 1. Hence, we can surmise the recall@k formula is equal to 1 if the relevant image is among the top \(k\) images else it’s 0. This metric measures a model’s ability to find the associated image for a given text text query however, despite being intuitive and easy to derive, this metric is not without its faults which includes:
- It depends on the choice of \(k\) and choosing the right \(k\) could be challenging.
- When the relevant image is not among the \(k\) images in the output list, recall@k is always \(0\). For instance, suppose a model X ranks a relevant image at place 15, and another model Y ranks the same image at place 20. If we use recall@10 to measure the quality of both models, both would have a recall@10 = 0, even though model X is better than model Y.
Mean Reciprocal Rank (MRR)
This metric measures the quality of the model by averaging the rank of the first relevant image in the search result where \(m\) is the total number of output lists and \(rank_{i}\) refers to the rank of the first relevant image in the \(i^{th}\) ranked output list.
\[ MRR = \frac{1}{m} \sum_{i=1}^{m}\frac{1}{rank_{i}} \]
This metric adrresses the limitations of recall@k and can be used as our offline metric.
4.2. Online metrics
In this section, we explore some commonly used online metrics for measuring how quickly users can discover product images they like. Online metrics are metrics tied to a user’s activity that can be translated to business outcomes, they include click-through rate (CTR), average duration spent on suggested images, average revenue from suggested images, etc.
Click-through rate (CTR)
This metric shows how often users click on the displayed images. CTR can be calculated using the formula:
\[ CTR = \frac{\text{Number of clicked images}}{\text{Total number of suggested images}} \]
A high CTR indicates that users click on the suggested images often, however it does not indicate or track whether the clicked images are relevant or not.
Average duration spent on the suggested images
This metric shows captures how engaged users are with the recommended images. Duration varies according to business objective, it could be daily, weekly, monthly time measures in minutes or even hours. When the search system is accurate, we expect this metric to increase.
5. Serving
At serving time, the system displays a ranked list of product images relevant to a given text query. Figure 2.2 shows the prediction pipeline, text and image indexing pipeline. We will discuss each pipeline in detail.

5.1. Prediction pipeline
This pipeline consists of:
- Image visual search
- Text search
- Fusing layer
- Re-ranking service based on business rrequirements
Image visual search
This component encodes the search text query and uses the nearest neighbor service to find the most similar image embeddings to the text query embedding. To define the nearest neighbor search more formally, given a text query \(q\) and a set of other points \(S\), it finds the closest points to \(q\) in \(S\). Note that a text query embedding is a point in N-dimensional space, where N is the size of the embedding vector. Figure 2.23 shows the top 4 nearest neighborsr of text query \(q\). We denote the text query as \(q\), and other product images as \(x\).

Text search
Using Elasticsearch or MongoDB Atlas search, this component finds catalog images with titles and tags that are similar to the text query.
Fusing layer
This component takes two different list of relevant product images from the previous two steps and combine them into a new list of images.
The fusing layer can implemented in two ways, the easiest of which is to re-rank images based on the weighted sum of their predicted relevance scores [1]. An Alternative is to train a machine learning model that predicts the likelihood of user interaction (e.g., click, purchase) of each image based on user’s history of activities and re-rank the displayed images. However, this approach is more expensive because it requires model training. Also, it is slower at serving hence the previous approach is preferred.
5.2. Image indexing pipeline
A trained image encoder is used to compute image embeddings, which are then indexed. All images on the catalog are indexed by nearest neighbor services to improve search performance. Another responsibility of the indexing service is to keep the index table updated. For example, when a new product is added to the catalog, the service indexes the embedding of the new product to make it discoverable by the nearest neighbor search.
[1] Indexing increases memory usage because we store the embeddings of the entire catalog images in an index table. There are different nearest neighbor (NN) algorithms such as Exact nearest neighbor and Approximate nearest neighbor (ANN). However, we won’t be describing them. In addition, various optimizations are available to reduce memory usages such as vector quantization, product quantization which we won’t discuss either.
5.3 Text indexing pipeline
Elasticsearch is used by this component to index titles, manually created tags, and automatically produced tags. In most cases, when users upload product images, they include tags to aid in image identification. But what if they don’t manually enter tags? One choice is to generate tags using a standalone model. This element, which we refer to as the “auto-tagger,” uses a model to produce tags. The auto-tagger, is particularly useful when a product image lacks manual tags. Although these tags make more noise than manual tags, they are nonetheless useful.
Conclusion
It’s vital to keep in mind that while we have simplified the system design for product search in e-commerce platforms, it is actually considerably more complex. Other elements such as adding popularity and freshness, increasing product features and user interaction, expanding text queries to support other languages, etc. were not included in this design.
[11] provides an overview of the offline-online, retrieval-ranking pattern for search and recommendations used by major companies such as Alibaba, Facebook, LinkedIn, etc. They also distinguish the latency-constrained online systems from the less-demanding offline systems, and split the online process into retrieval and ranking steps.
Citation
Thanks to Ali Aminian & Alex Xu (2023) for their book as it inspired and provided the framework for this article.
To cite this content, please use:
Olaniyi, Babaniyi (Mar 2023). Designing a Recommendation System for Search in E-Commerce. babaniyi.com. https://www.babaniyi.com/2023/03/22/designing-a-recommendation-system-for-search-in-ecommerce.html
@article{olaniyi2023search-system,
title = {Designing a Recommendation System for Search in E-Commerce} ,
author = {Babaniyi Olaniyi},
journal = {babaniyi.com},
year = {2023},
month = {Mar},
url = {https://www.babaniyi.com/2023/03/22/designing-a-recommendation-system-for-search-in-ecommerce.html}
}
References
- Ali Aminian & Alex Xu (2023). Machine Learning System Design Interview.
- Full Text Search with MongoDB
- How To Improve Database Searches with Full-Text Search
- Elastic Search
- Preprocessing text data
- An Overview of Text Representation in NLP
- NLP text encoding
- Word2Vec
- ResNet
- A Simple Framework for Contrastive Learning of Visual Representations
- Yan, Ziyou. (Jun 2021). System Design for Recommendations and Search